
Which source strategy fits your scenario?
Four common content patterns, and what we'd do for each if we were starting over today.
Thirty-plus sites. Fifteen languages. One search platform unifying them all. What we learned rebuilding enterprise search at global scale — and the decisions we'd undo tomorrow if we could.
At 2:47 in the morning, a product manager in Tokyo typed a query into our site. The search returned zero results. Across the globe, a user in Berlin searched the exact same product — and got 847 results, ranked in what could only charitably be called "random order." Both were looking at the same catalog, the same brand, the same company. Neither got what they wanted.
This is the story of how we fixed that. More importantly, it's the story of everything we got wrong along the way — and why the lessons that mattered most weren't technical at all.
If you're running Sitecore Search — or evaluating it, or inheriting it from the person who set it up and then left — this is for you. There are lessons here you won't find in the documentation.
01 — The Scale Problem
What "30+ Sites" Actually Means
When leadership says "we have thirty sites," what they usually picture is thirty copies of the same website in different languages. What it actually means, in practice, is thirty independent content ecosystems, each with their own editorial team, their own taxonomy decisions made three years ago by someone who's since left the company, their own regional compliance quirks, and their own opinions about what "relevance" means.
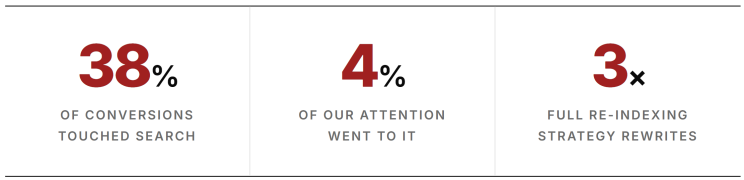
Our footprint broke down roughly like this: twelve flagship product sites across North America, EMEA, and APAC; eight regional marketing hubs with localized campaigns; six partner portals with gated content; and a handful of microsites for specific product launches that somehow never got decommissioned. Fifteen languages. Four distinct content models. Three legacy CMSs feeding into Sitecore. One very ambitious timeline.
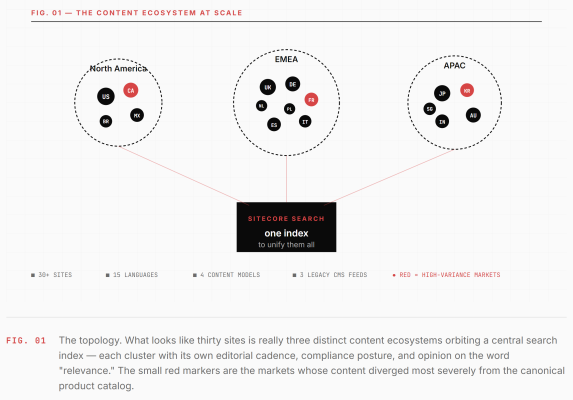
The real scale problem isn't the number of sites. It's that each site represents a different answer to the question: what is this content for? A product page in Japan is a specification document. The same product in Brazil is a marketing narrative. In Germany it's a compliance artifact. One search engine has to make all of them findable, rankable, and useful — and it has to do it without picking favorites.

02 — The Decision
Why Sitecore Search, and Why Not the Others
We evaluated four serious contenders: Coveo, Algolia, self-hosted Elasticsearch, and Sitecore Search. The spreadsheet took six weeks. The decision took fifteen minutes in a conference room once we finally admitted what we were actually optimizing for.
Algolia was the fastest. Coveo had the most mature AI relevance. Elasticsearch gave us the most control. But we already had Sitecore XM Cloud as our content platform across most of the portfolio, and the integration story — content source federation, native personalization hooks, unified analytics with the rest of the DXP — turned out to matter more than any individual feature comparison. The headless architecture let us keep our frontends intact while swapping the search brain underneath.
What we accepted as trade-offs: a smaller ecosystem of third-party extensions, a learning curve for teams used to Elasticsearch's query DSL, and pricing that made finance ask questions quarterly. What we got: a platform that understood what a "content hub" meant without us having to explain it.
03 — Architecture
Decisions That Aged Well (and Those That Didn't)
Every search architecture is a bet on what will stay stable. Ours involved three big calls. Two of them we'd make again. One of them we spent six months unwinding.
The source strategy (we'd do it again)
We chose one source per site rather than a unified source across all sites, and then federated at query time. This felt wasteful — we had 30+ sources to configure and maintain — but it gave us per-site control over crawl frequency, attribute extraction rules, and the ability to recover from a broken deploy in one market without taking down search globally. When the Japanese team pushed a schema change that broke their content ingestion, nobody else noticed.
The locale handling (we'd do it again, nervously)
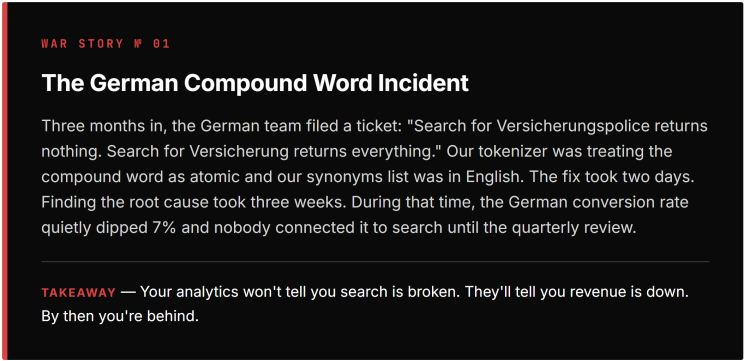
We treated locale as a first-class filter rather than embedding it in the source itself. One index, locale as a facet, boosts applied at query time based on the requesting domain. This gave us the ability to do cross-locale searches (useful for multinational users) but meant our relevance tuning had to be locale-aware in ways we didn't anticipate. German compound words broke our synonym logic for three months before we figured out what was happening.
The attribute extraction (we'd undo it tomorrow)
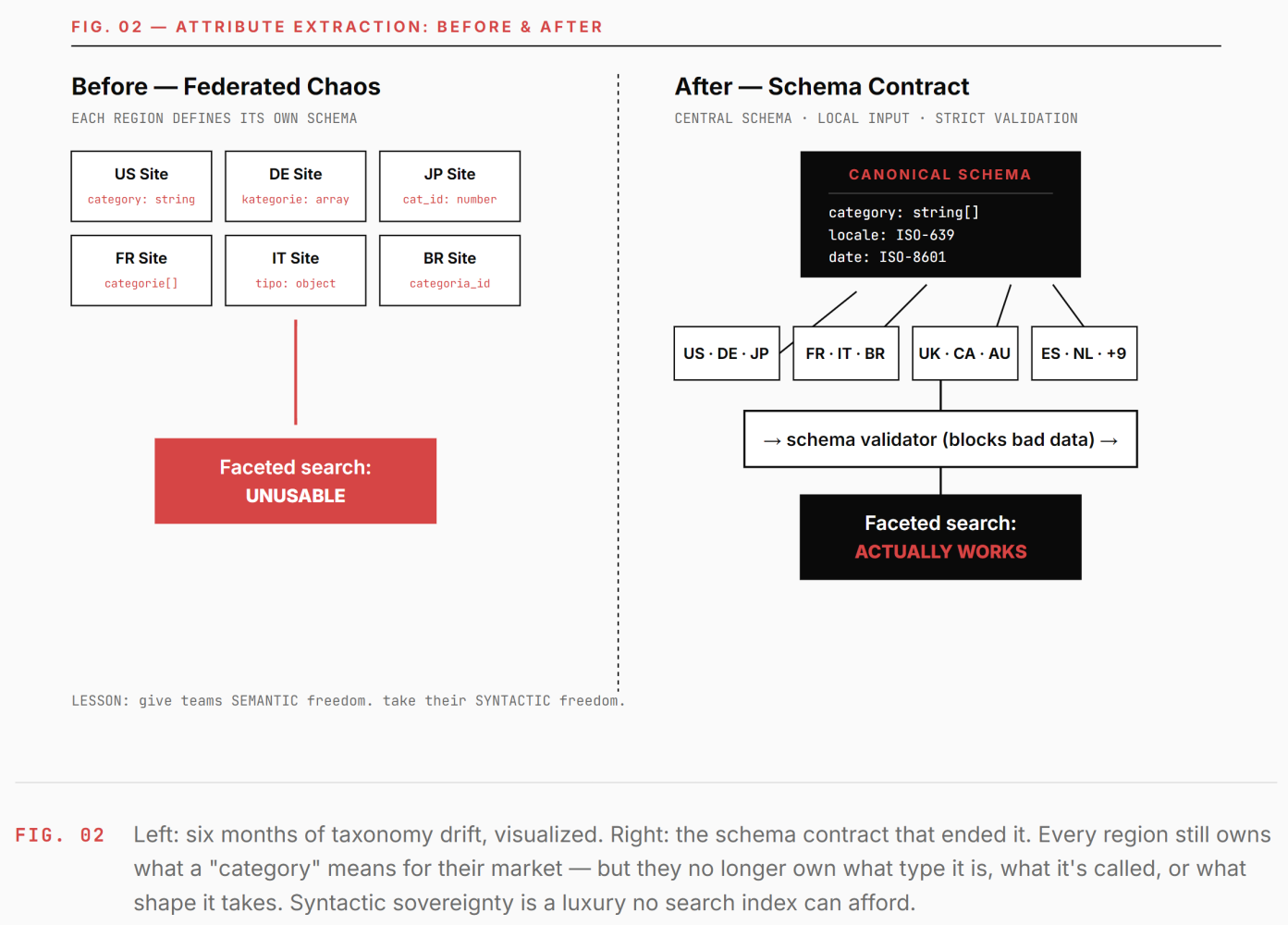
We trusted each regional team to define their own extraction rules, figuring they knew their content best. They did. What they didn't know was what other regions were doing. We ended up with fourteen different ways of encoding "product category," seven different date formats, and a taxonomy drift problem that made faceted search nearly useless for six months. Centralizing this — with strong local input but non-negotiable schema contracts — was the single most impactful fix we made.
Which source strategy fits your scenario?
Four common content patterns, and what we'd do for each if we were starting over today.

04 — Content Chaos
The Problem Nobody Warns You About
Search relevance is a content problem dressed up as an engineering problem. You can tune boost weights for months and still get worse results than you'd get by fixing three fields in your CMS. Nobody tells you this at the start, because the people who know it are usually too busy fixing fields.
Our editorial teams had inherited taxonomy decisions from platform migrations long before anyone was thinking about search. "Product type" meant one thing in the North American catalog and something entirely different in EMEA. Translation teams were optimizing for brand voice, not for keyword coverage — which is exactly what you'd want from a translation team, except that it left massive gaps where users searched in consumer language and our content spoke in marketing language.
The hardest fights weren't technical. They were political. Whose taxonomy wins when US marketing says "solutions" and UK says "services" and they're the same thing? Who owns the synonym list? What happens when the German team wants to boost a regional product that doesn't exist in any other market? These are governance questions masquerading as search questions, and they're the ones that will kill your project if you don't resolve them before you start tuning relevance.
05 — Relevance
Tuning at Scale, Honestly
Here's the uncomfortable truth about relevance tuning across thirty sites: every boost you add for one market is, implicitly, a decision you're making for all the others. Unless you scope everything locale-specifically — which creates an unmanageable rule explosion — you're going to ship policies that work brilliantly in English and terribly in Japanese.
We settled on a three-tier approach. A global baseline handles universal rules (recent content gets a mild boost, deprecated products get demoted, exact title matches always win). A regional layer adds market-specific business rules. A locale layer handles language-specific quirks (tokenization, stemming, synonyms). Each tier is owned by a different team, with clearly defined boundaries about what they can change without cross-team review.
The hardest part wasn't building this. It was convincing the marketing team in each region that they didn't, in fact, need to be able to manually pin their pet product to the top of every query that vaguely touched their category. Some of them are still convinced we're wrong about this.
What weight tuning actually looks like
A snapshot from our production config for the query "enterprise security platform." Five signals, weighted. The resulting ranking is on the right — and every number on the left changes that ranking.

06 — Analytics
The Reality Check
Six weeks after launch, we pulled our first comprehensive search analytics report. It was humbling. The queries we'd optimized for were not the queries users were running. The zero-result searches that we'd treated as edge cases were thirty percent of total volume in some markets — and most of them were content gaps, not search failures. Users were asking questions our content wasn't written to answer.
The most valuable thing we built in that first year wasn't a search feature. It was a weekly report that went to the content strategy team showing the top zero-result queries by market, filtered by volume and commercial intent. That report changed editorial priorities across the company. Within six months, our "search gap" — the delta between what users asked for and what we had content about — had shrunk by 60%.

07 — Operations
Indexing War Stories
There's no glamour in the operational side of running search at scale. It's reindexing strategies, publish storms, rate limits, and the steady accumulation of edge cases that nobody documents because documenting them would take longer than fixing them. But it's also where most production outages live.
Our worst incident happened six months in. A marketing team in one region did a major content cleanup — deleting and republishing several thousand items over a weekend. The resulting indexing queue consumed API quota globally, and for about four hours, search results in every market were stale by up to a day. Our SLA didn't cover staleness, only availability, so technically nothing was "down." In practice, everything was broken.
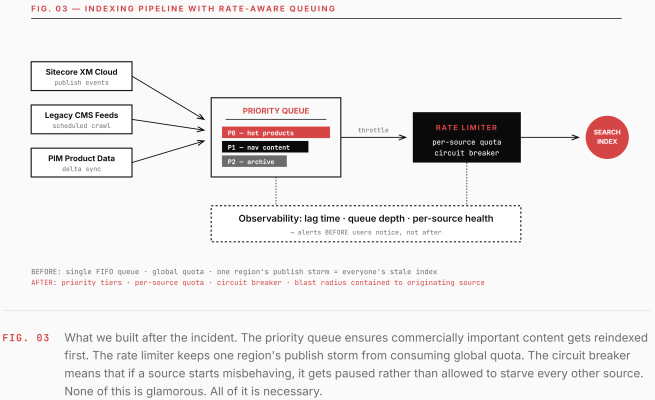
08 — Governance
The Soft Stuff Is the Hard Stuff
If I could go back and give myself one piece of advice on day one, it would be this: the hardest problems in enterprise search are organizational, not technical. You're going to spend more time in meetings debating who owns the synonym list than you will writing any code that matters. Accept this. Plan for it. Build governance structures before you think you need them.
We eventually landed on a search governance board with three permanent seats — platform engineering, content strategy, analytics — and rotating regional representation. It meets every two weeks for forty-five minutes. It makes binding decisions about schema changes, relevance policy, and cross-market escalations. It was the single most valuable structure we created, and we fought it for nine months before admitting we needed it.

09 — Metrics
Beyond Click-Through Rate
Click-through rate is the cholesterol of search metrics. Easy to measure, easy to communicate, almost meaningless in isolation. A user clicking the first result doesn't mean the first result was right. It might mean the user gave up on finding the right answer and settled for something plausible.
The metrics that actually moved our roadmap: time to first meaningful interaction (how long until a user did something that suggested they'd found what they came for); reformulation rate (what percentage of searches were followed by another search, indicating the first one failed); search-originated conversion rate segmented by query type; and zero-result rate filtered by commercial intent. None of these are in the default dashboard. All of them we had to build.
Takeaways
Five Things I Wish I'd Known on Day One
Here's what I'd tell past-me, if I could find him at the start of this project and buy him a coffee before he made several of these decisions:
- Don't start with relevance. Start with content hygiene. Every hour you spend on relevance tuning before your metadata is clean is an hour you'll repeat when the data finally gets cleaned up. Schema contracts first, taxonomy audits second, relevance third. The order matters more than the speed.
- Your best search engineer is a content strategist in disguise. Technical search problems are usually content problems wearing a jacket. The person who fixes search the fastest is almost never the person with the deepest knowledge of Solr or Elasticsearch. It's the one who understands what the content is supposed to do.
- Governance is infrastructure. Build it early. The governance board you think you can defer is the governance board that will be created reactively, in crisis, after an incident you could have prevented. Build it before you need it. Make it boring. Boring governance is working governance.
- Measure things that hurt to measure. Zero-result rates. Reformulation rates. Search-to-abandonment. These metrics will make you look bad in dashboards. They're also the only ones that will tell you when something is actually broken. If all your search metrics are green, they're probably lying to you.
- Ship the feedback loop to content teams first. Before you tune a single boost weight, make sure the team writing the content can see what users are searching for and failing to find. Content teams fix search problems at their root. Engineers fix them at the leaves. Both matter. One scales better than the other.






